

Most people do not begin with chords, stems, or arrangement charts. They begin with language. They know the song should feel weightless, restless, romantic, mechanical, bright, or unresolved. The reason an AI Music Generator platform can feel useful is that it starts closer to that natural way of thinking. Instead of forcing users to translate emotion into production terminology too early, it lets them begin with descriptive intent and then move toward musical form.
That sounds simple, but it changes creative behavior. When a writing tool or visual editor becomes easier to use, people usually produce more drafts. Music is no different. Once sound can be prompted, structured, regenerated, and compared with less friction, creators become more willing to test alternatives rather than settle for the first decent option. In my observation, that is one of the more important shifts in AI music creation right now.


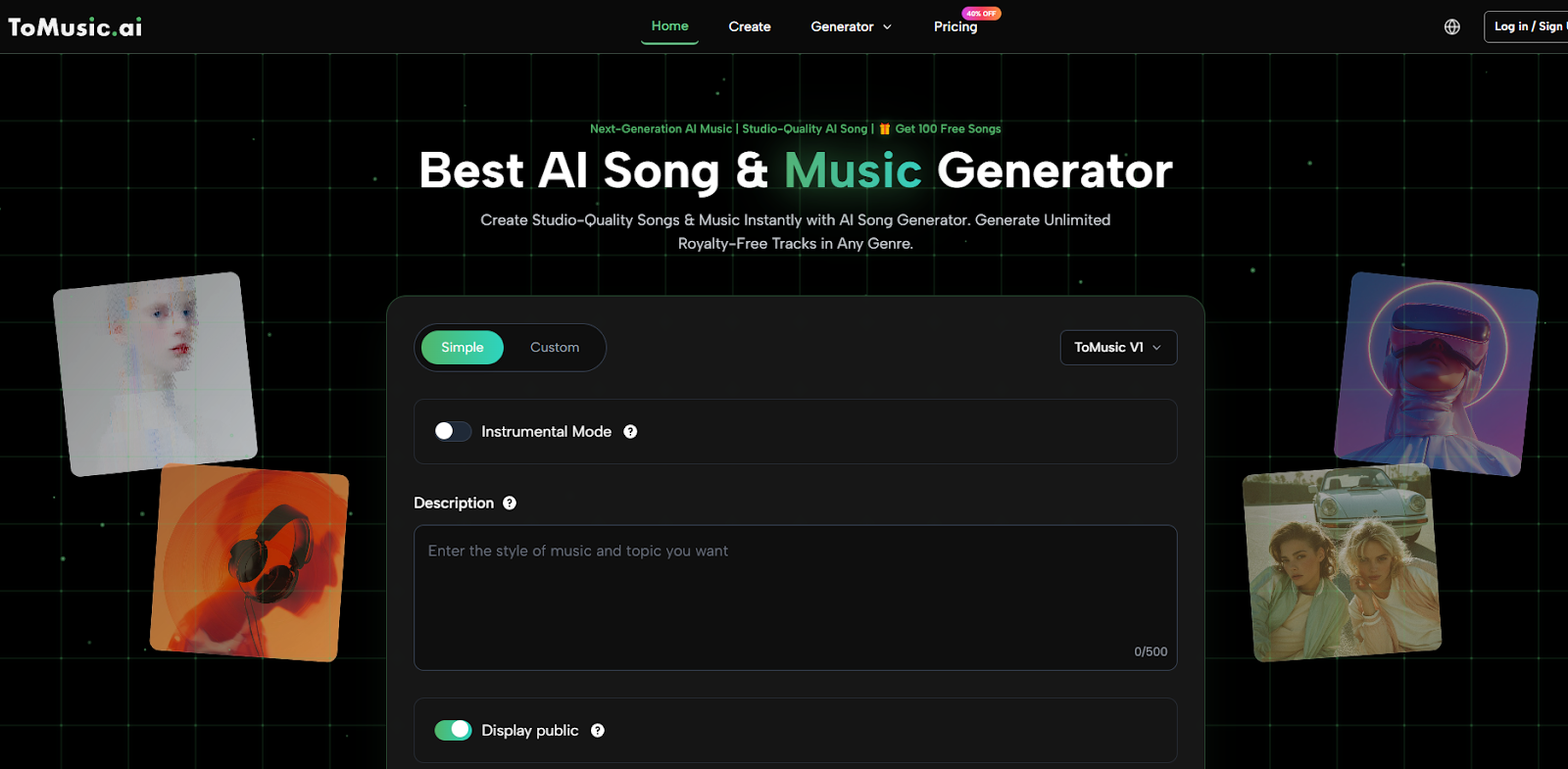
The specific platform structure reinforces that idea. The creation interface shows two modes, an instrumental switch, model selection, and separate fields for title, styles, and lyrics, along with musical selectors for genre, moods, voices, and tempos. That layout matters because it gives users a ladder from rough language to more organized musical control. It is not fully manual composition, but it is also not blind automation.
Why Natural Language Matters In Music Work
The older assumption in music software is that control must come first. You open a project, choose instruments, set timing, place notes, and only then does the piece become audible. That remains powerful for trained users, but it is not how many modern creators think when they are trying to ship something.
Language Is Closer To Creative Intent
A content creator may not know which chord inversion makes a scene feel warmer, but they do know they want warmth without sentimentality. A startup founder may not know sound design vocabulary, but they know they need an intro that feels trustworthy rather than dramatic. Natural language is closer to the way these decisions are actually formed.
Structured Inputs Turn Vague Ideas Into Usable Constraints
The platform does something practical by separating styles, lyrics, tempo-related choices, mood-related choices, and voice-related choices. This turns a fuzzy request into a set of manageable constraints. That is often where better outputs begin.
Music Becomes Easier To Compare
Once creation is driven by structured language, comparison gets easier. You can keep the same lyrics and shift the model. You can keep the mood and remove vocals. You can preserve the core idea while testing different stylistic frames. That is a better workflow than replacing everything at once.
Reading The Platform As A Creative System
A useful way to understand the product is not as a black box, but as a sequence of decisions the interface is encouraging users to make.
The Mode Choice Sets The Creative Depth
Simple mode seems designed for speed. It is the route for people who want to move quickly from description to result. Custom mode, by contrast, suggests a more deliberate creative posture. Once title, style, and lyrics become separate entries, the user is already thinking more like an editor than a casual prompt writer.
Instrumental Output Extends The Audience
The visible instrumental option broadens the product beyond lyric-based songs. It makes the same engine relevant for intros, underscore, background layers, and creator music that should support content rather than dominate it.
Credits Make The Generation Cost Explicit
The page also shows a credit requirement before generation. I actually like that clarity. It makes experimentation measurable. Users know that generating is an action with a visible cost, which can lead to more deliberate testing rather than endless random retries.
How The Different Models Likely Change Use
The visible V1 through V4 ladder is one of the stronger signals on the site because it suggests the company expects users to choose an engine based on purpose.
V1 Works For Quicker Draft Cycles
The product pages present V1 as a balanced, faster option with four-minute output and practical lyric support. For creators making repeat content, that is probably the most efficient starting point.
V2 Builds Toward More Atmosphere
V2 is framed around tonal depth and longer compositions. To me, that reads as a model better suited to ambient, cinematic, or slower-form material where texture matters more than immediate hooks.
V3 Adds Arrangement Complexity
The language around V3 emphasizes richer rhythmic patterns and stronger harmonic development. That suggests more internal movement within the piece, which could matter for users who want the result to feel more composed than merely generated.
V4 Focuses On More Convincing Vocals
V4 is positioned as the flagship with the strongest vocals and full eight-minute length. In practical terms, that likely matters most for lyric-driven work where the vocal carries the identity of the piece.
The Workflow In Four Practical Steps
The site itself supports a short process, and that brevity is part of the appeal.
Step One Chooses The Creation Frame
Start in the generator and choose either Simple or Custom mode. Then select the model and decide whether the track should include vocals or remain instrumental.
Step Two Defines The Musical Direction
If using Custom mode, enter the title, styles, and lyrics. Then use the visible categories for genre, moods, voices, and tempos to narrow the musical behavior.
Step Three Generat♥es The Track
Generate the result using the required credits shown on the page. This is where the abstract request becomes an actual musical draft.
Step Four Reviews, Downloads, Or Refines
Listen to the output, decide whether it fits the creative goal, then refine inputs or export the track. That is where Text to Music becomes operational rather than theoretical, because the value lies in the ability to move from draft to revision without restarting the whole process.

What The Export And Plan Details Reveal
A pricing page often says more about product intent than a slogan does. The features listed there indicate which outputs the company considers serious enough to monetize.
| Product Detail | Visible On The Site | Practical Reading |
| Free tier with one-time song quota | Yes | Lets users test without immediate commitment |
| V1 only on free plan | Yes | Suggests advanced model access is a paid differentiator |
| Four-minute songs on free plan | Yes | Enough for testing and shorter content |
| Up to eight-minute songs on paid plans | Yes | Better for full compositions and extended pieces |
| WAV and MP3 download | Yes | Designed for reuse outside the platform |
| Stem extraction and vocal removal | Yes | Supports post-production flexibility |
| Commercial license | Yes | Signals creator and business use cases |
| Concurrent generation limits | Yes | Encourages faster comparison workflows |
This set of features makes the platform easier to place. It is not just a consumer novelty. It is attempting to serve both casual creators and users who need exports, variations, and more usable downstream assets.
Where This Can Be Genuinely Useful
I think the clearest use cases are the ones where music does not need to emerge from a long specialist pipeline.
Short-Form Content Production
When social content needs rapid testing, a team can evaluate multiple musical directions early. One version may feel too glossy, another too heavy, another finally right. That kind of comparison is easier when regeneration is built into the workflow.
Early Narrative Prototyping
Music changes how a scene is interpreted. A draft soundtrack can reveal whether a concept feels intimate, playful, dramatic, or too polished. In early-stage storytelling, that is a meaningful advantage.
Lyric-Based Experiments
Because the system supports direct lyric entry, users with written material can hear different interpretations of the same words. Even when the first result is imperfect, it can act as a compositional mirror and help refine the writing itself.
What Users Still Need To Understand
No matter how convenient the interface becomes, a few constraints remain.
Good Inputs Still Require Precision
In my observation, the better the prompt language and style framing, the less generic the output feels. If a user only writes broad requests, the track may sound broadly competent but not distinctive.
Higher Output Does Not Always Mean Better Fit
A more advanced model or longer track may sound more impressive in isolation, yet still be wrong for the project. Fitness matters more than technical ambition.
Revision Is Still Part Of The Process
The tool shortens the distance between intention and audio, but it does not remove iteration. Users should expect to regenerate, compare, and refine rather than assume the first draft will solve the whole brief.
Why This Category Is Becoming More Relevant
The real significance of AI music is not simply that it can make songs from text. It is that it gives non-specialists a structured path into musical decision-making. Once language, lyrics, mood, tempo, and model choice are enough to create a usable draft, sound becomes easier to include in earlier creative thinking.
That matters because many projects do not fail from lack of ideas. They stall because the team cannot test those ideas fast enough. A platform like this is interesting when it helps music behave more like a flexible design material instead of a late-stage bottleneck. In that role, its value is easier to understand and easier to trust.










{kind=link}